Introduction
Introduction
It is one thing to train ad-hoc end to end models and another to create repeatable, reusable machine learning worflows. Afterall what is the purpose of training the most accurate models if it is cost prohibitive to do so.
This section is about machine learning operations, also known as MLOps.
Topics covered:
- Data processing pipelines
- Kubeflow
- Tensorflow Extended
- Docker containers
- GPUs
series in this website and is a very brief but important introduction about how GPUs operate, why it is important to understand and how this understanding can help you speed up productionalize models while keeping infrastructure costs low.
GPUs
Understanding how GPUs work is useful for making the best decisions about how to operate the right infrastructure to train and predict efficiently.
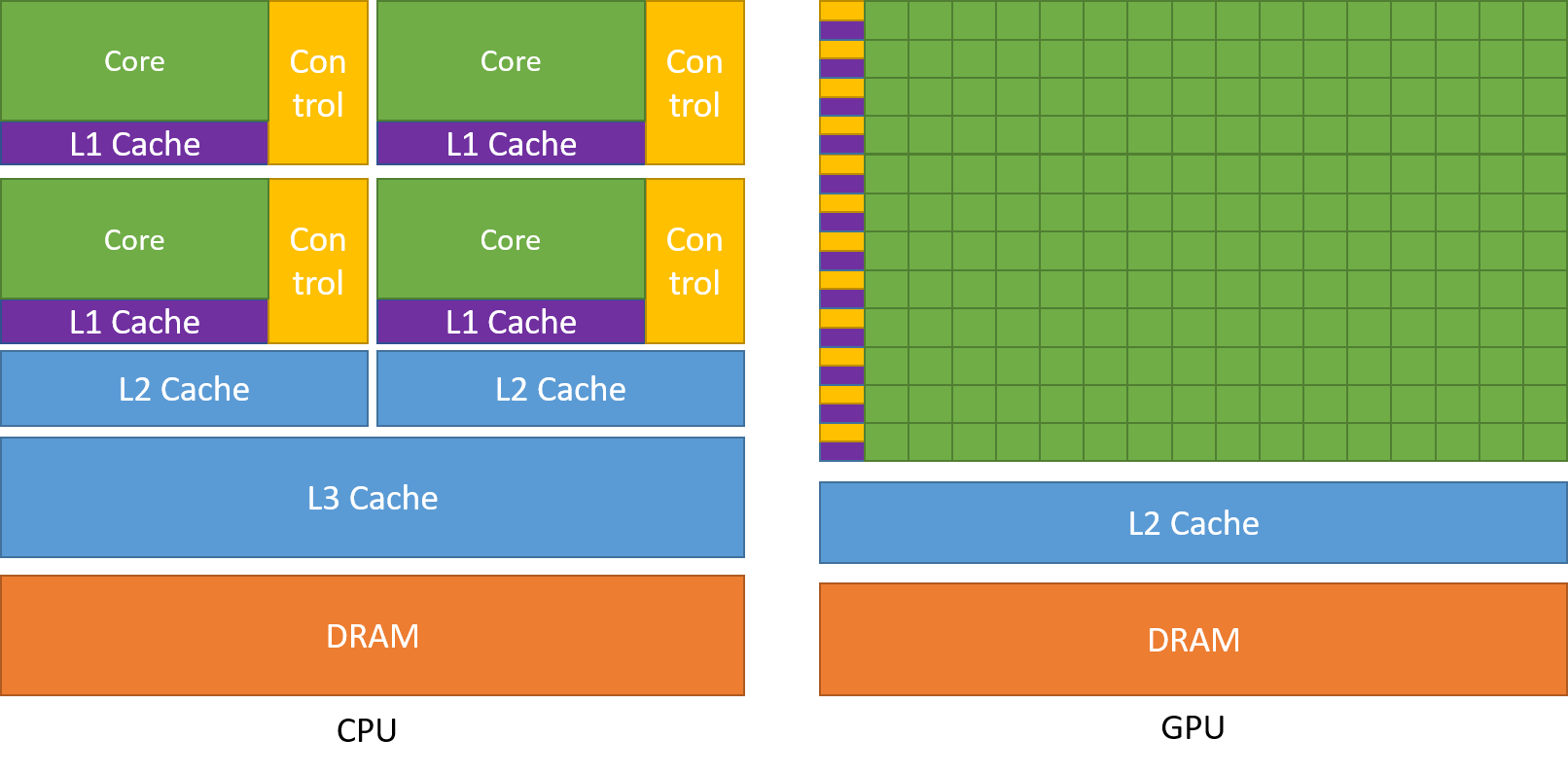
CPUs are designed to excel at executing a sequence of operations as fast as possible and can execute a few tens of these threads in parallel.
GPUs are designed to excel at executing thousands of threads in parallel. They are specialized for highly parallel computations and designed such that more transistors are devoted to data processing rather than data caching and flow control.
CUDA
CUDA is a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs.
To explain the concepts more simply and without C++ knowledge, this section will use numba, an open source JIT compiler that translates a subset of Python and NumPy code into fast machine code.
Think of numba like a python abstraction for CUDA C++ programming. The concepts are all the same regardless of using numba or CUDA C++ kernels.
Terminology
- host: the CPU
- device: the GPU
- host memory: the system main memory
- device memory: onboard memory on a GPU card
- kernels: a GPU function launched by the host and executed on the device
- device function: a GPU function executed on the device which can only be called from the device (i.e. from a kernel or another device function)
As stated in the terminology, a kernel is a function a programmer writes in order to perform an operation. The key concept here is that a kernel is executed N times in parallel by N different CUDA threads, as opposed to once like a regular C++ or python function.
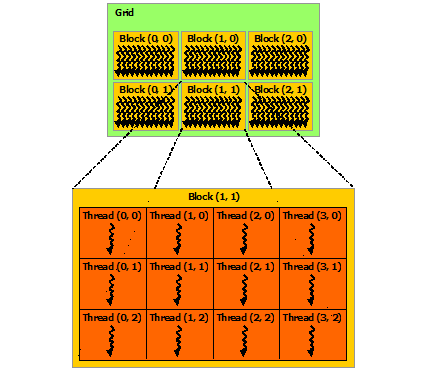
Numba and CUDA both have special objects for the sole purpose of knowing the geometry of the thread hiarchy. These objects can be 1D, 2D or 3D. Lets break down this statement into simpler terms.
Remember that a GPU is good at running thousands of threads in parallel, and a kernel is executed N times in parallel by N different CUDA threads. That means that in order to keep track of which thread is executing a particular operation on lets say a vector or matrix, we need to know its “position”. This can be found by the special object numba.cuda.threadIdx. And because these objects can be 1D, 2D or 3D, then this can be a tuple with up to 3 elements.
Multiple threads live inside a block where they share some memory and are executed in parallel. A thread block may contain up to 1024 threads. The block “position” can be found by the special object numba.cuda.blockIdx. And because these objects can be 1D, 2D or 3D, then this can be a tuple with up to 3 elements.
Multiple blocks are combined into a grid. The shape of the block of threads can found by the special object numba.cuda.gridDim. This value is the same for all threads in a given kernel, even if it belongs to different blocks.
Finally, the special object numba.cuda.grid returns the absolute position of the current thread in the entire grid of blocks.
Here is an example to concretize the concepts. Here is a kernel that takes an array and increments each value by 1.
@cuda.jit
def increment_by_one(an_array):
# Thread id in a 1D block
tx = cuda.threadIdx.x
# Block id in a 1D grid
ty = cuda.blockIdx.x
# Block width, i.e. number of threads per block
bw = cuda.blockDim.x
# Compute flattened index inside the array
pos = tx + ty * bw
if pos < an_array.size: # Check array boundaries
an_array[pos] += 1
In order to call this kernel we need to provide the number of threads per block and blocks per grid needed in order to run this in parallel. For example:
an_array = np.zeros(500)
threadsperblock=32
blockspergrid=len(an_array) + (threadsperblock-1)
increment_by_one[blockspergrid,threadsperblock](an_array)
Notice that when calling the kernel, two variables are provided based on the size of the array being passed and although it seems like the kernel is being called once, it is actually running hundreds of threads in parallel, each one increasing the value at pos by 1. This is why the if statement is checking that pos is less than the array size because it is likely we will spawn more threads than needed.
Another point to make is that the first time this kernel is run, it is compiled, so it takes longer to run than subsequent calls.
Kernels cannot explicitly return a value, all result data must be written to an array passed to the function (if computing a scalar, you will probably pass a one-element array)
Here is an example of this using matrix multiplication.
@cuda.jit
def matmul(A, B, C):
"""Perform square matrix multiplication of C = A * B
"""
i, j = cuda.grid(2)
if i < C.shape[0] and j < C.shape[1]:
tmp = 0.
for k in range(A.shape[1]):
tmp += A[i, k] * B[k, j]
C[i, j] = tmp
And call the kernel like:
threadsperblock=(32,32)
blockspergrid=(16,16)
A = np.random.rand(300,200)
B = np.random.rand(200,300)
C = np.zeros((200,200))
matmul[blockspergrid,threadsperblock](A,B,C)
When timing the above kernel, it takes longer than when running the same computations using a numpy array on a CPU. The above kernel is running hundreds of parallel threads, how can that be so?
This is because before the kernel can spawn and run multiple threads in parallel it needs to copy the data from the host memory (CPU) to the device memory (GPU). A numpy calculation on a CPU doesn’t have that overhead so it outperforms the GPU implementation.
This problem can be mitigated by copying the data to the GPU ahead of time and running then running the kernel. This can be done as follows:
threadsperblock=(32,32)
blockspergrid=(16,16)
A = np.random.rand(300,200)
A_cuda = cuda.to_device(A)
B = np.random.rand(200,300)
B_cuda = cuda.to_device(B)
C = np.zeros((200,200))
C_cuda = cuda.to_device(C)
matmul[blockspergrid,threadsperblock](A,B,C)
In this particular example, the result is the same. However, imagine, for example, where batch image predictions are necessary. Then copying the images to the GPU first and then running a model with the images already loaded on GPU memory, this greatly outperforms CPU by several orders of magnitude. This technique can save hundreds or thousands of infrastructure costs.
Sources
Resources used for this page