Introduction
Introduction
fingym makes no assumptions about the structure of your agent, and is compatible with any numerical computation library, such as Tensorflow or Theano.
The agent sends actions to the environment, and the environment replies with observations and rewards (that is, a score).
Here we defined a couple of agents to understand this concept and get you started.
Buy and hold agent
Our favorite holding period is forever - Warren Buffett
This code creates a SPY-Daily-v0 environment an agent that buys as many shares as it is allowed from the initial investment and holds it through the whole episode.
Run examples/agents/buy_and_hold_agent.py
The Agent is very simple.
class BuyAndHoldAgent(object):
def __init__(self, action_space):
self.bought_yet = False
def act(self, observation, reward, done):
if not self.bought_yet:
cash_in_hand = observation[1]
close_price = observation[6]
num_shares_to_buy = cash_in_hand / close_price
print('will buy {} shares'.format(num_shares_to_buy))
self.bought_yet = True
return [1,num_shares_to_buy]
else:
return [0,0]
First time this agent acts, it buys as many shares as it can based on the amount of cash in hand, then just holds it through the rest of the episode.
The cash in hand and close prices come from the observation observation object. You can read more about observation (also refered to as the state) here.
Run the episode:
env = fingym.make(args.env_id)
agent = BuyAndHoldAgent(env.action_space)
reward = 0
done = False
cur_val = 0
ob = env.reset()
initial_value = ob[1]
while True:
action = agent.act(ob, reward, done)
ob, reward, done, info = env.step(action)
if done:
cur_val = info['cur_val']
break
print('initial value: {}'.format(initial_value))
print('final value: {}'.format(cur_val))
We run through the episode until done is true. Finally we print the intial and final value. The results:
will buy 290.15784586815226 shares
initial value: 25000.0
final value: 92848.52999999987
This agent has an extremely successful investment strategy over a long period of time. Can we do better?
Random agent
Give a monkey enough darts and they'll beat the market. - Research Affiliates
This code creates a SPY-Daily-v0 environment and agent that makes random actions throughout the episode.
Run examples/agents/random_agent.py
This agent is even simpler than the buy and hold agent:
class RandomAgent(object):
def __init__(self, action_space):
self.action_space = action_space
def act(self, observation, reward, done):
return self.action_space.sample()
For this agent, we will run 100 episodes and get a min, average and max values to create a distribution. This is because one data point is not enough to evaluate this strategy. The more episodes we run, the better distribution we create.
env = fingym.make(args.env_id)
agent = RandomAgent(env.action_space)
episode_count = 100
reward = 0
done = False
final_vals = []
initial_value = 0
for i in range(episode_count):
ob = env.reset()
initial_value = ob[1]
while True:
action = agent.act(ob, reward, done)
ob, reward, done, info = env.step(action)
if done:
final_vals.append(info['cur_val'])
break
max_value = max(final_vals)
min_value = min(final_vals)
avg_value = sum(final_vals)/len(final_vals)
print('initial value: {}'.format(initial_value))
print('min_value: {}, avg_value: {}, max_value: {}'.format(min_value,avg_value,max_value))
Results
initial value: 25000.0
min_value: 34758.73830000002, avg_value: 49393.79445500023, max_value: 75881.42879999822
Even random actions generate good returns in the long run, however, not as good as a buy and hold strategy.
Deep Q learning
This code creates a SPY-Daily-v0 environment and a deep reinforcement learning agent based on q learning and the Bellman equation. This section is not an introductory course to q learning. Instead it focuses on implementation of a deep q learning agent for the fingym environment.
This agent requires tensorflow, as of Feb. 12 2020, we recommend the nightly build due to a memory leak issue.
Run examples/agents/dqn_agent.py
The agent builds two identical networks, the q and target networks. Additionally we set a epsilon decay to reduce exploration as training cycles increase. Finally a replay buffer is used for training.
We are using fully connected neural networks, and our model takes time frame sequence data as inputs. For example, if we are using the last 5 days of data then the input size is state_size*time_frame.
class DQNAgent():
def __init__(self, env_state_dim, time_frame, epsilon = 1, learning_rate=0.01, train = False):
dirname = os.path.dirname(__file__)
self.model_filepath = os.path.join(dirname,'weights.h5')
self._state_size = env_state_dim
self.trainMode = train
# 0 - do nothing
# 1 - buy w/ multiplier .33
# 2 - buy w/ multiplier .5
# 3 - buy w/ multiplier .66
# 4 - sell w/ multiplier .33
# 5 - sell w/ multiplier .5
# 6 - sell w/ multiplier .66
self._action_size = 7
self.experience_replay = deque(maxlen=2000)
self.gamma = 0.98
if not self.trainMode:
self.epsilon = 0
else:
self.epsilon = epsilon
self.eps_decay = 0.995
self.eps_min = 0.01
self.max_shares_to_trade_at_once = 100
# holds our last time_frame sequential state frames for prediction.
self._time_frame = time_frame
self.state_fifo = deque(maxlen=self._time_frame)
# networks
self.q_network = self._build_compile_model(learning_rate)
self.target_network = self._build_compile_model(learning_rate)
self._load_model_weights(self.q_network, self.model_filepath)
self.align_target_model()
def align_target_model(self):
# reduce exploration rate as more
# training happens
if self.epsilon > self.eps_min:
self.epsilon *= self.eps_decay
print('epsilon: ', self.epsilon)
self.target_network.set_weights(self.q_network.get_weights())
self._save_model_weights(self.q_network, self.model_filepath)
def _build_compile_model(self, learning_rate):
'''
Model taken from https://arxiv.org/pdf/1802.09477.pdf
'''
model = Sequential()
# use a dense nn with inputs
input_size = self._state_size * self._time_frame
model.add(Dense(400, input_shape=(input_size,), activation='relu'))
model.add(Dense(300, activation='relu'))
#model.add(Dense(self._action_size, activation='tanh'))
model.add(Dense(self._action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(learning_rate=learning_rate))
print(model.summary())
return model
def store(self, state, action, reward, next_state, terminated):
state = np.reshape(state, (self._state_size,self._time_frame))
next_state = np.reshape(next_state, (self._state_size, self._time_frame))
self.experience_replay.append((state, action, reward, next_state, terminated))
The output action size is 7. This model buys and sells shares in batches of max_shares_to_trade_at_once*multiplier. As follows:
Action space output:
0 - do nothing
1 - buy w/ multiplier .33
2 - buy w/ multiplier .5
3 - buy w/ multiplier .66
4 - sell w/ multiplier .33
5 - sell w/ multiplier .5
6 - sell w/ multiplier .66
The act function predicts when our state_fifo is full (state_size*time_frame) and based on our epsilon value:
def act(self, state):
self.state_fifo.append(state)
# do nothing for the first time frames until we can start the prediction
if len(self.state_fifo) < self._time_frame:
# Our environment takes a tuple for action https://entrpn.github.io/fingym/#spaces
return np.zeros(2)
# epsilon decays over time
if np.random.rand() <= self.epsilon:
return self._random_action()
state = np.array(list(self.state_fifo))
state = np.reshape(state,(self._state_size*self._time_frame,1))
q_values = self.q_network.predict_on_batch(state.T)
env_action = self._nn_action_to_env_action(np.argmax(q_values[0]))
return env_action
Finally, the network is retrained with stochastic gradient descent:
def retrain(self, batch_size):
if not self.trainMode:
return
minibatch = random.sample(self.experience_replay, batch_size)
for state, action, reward, next_state, terminated in minibatch:
state = np.reshape(state,(self._state_size * self._time_frame,1))
next_state = np.reshape(next_state, (self._state_size * self._time_frame, 1))
target = np.array(self.q_network.predict_on_batch(state.T))
if terminated[-1]:
target[0][np.argmax(self._nn_action_to_env_action(action))] = reward[-1]
else:
t = np.array(self.target_network.predict_on_batch(next_state.T))
target[0][np.argmax(self._env_action_to_nn_action(action))] = reward[-1] + self.gamma * np.amax(t)
self.q_network.fit(state.T, target, epochs=1, verbose = 0)
The full training loop takes care of filling up the replay buffer with the time frame data.
if __name__ == '__main__':
parser = argparse.ArgumentParser(description=None)
parser.add_argument('env_id', nargs='?', default='SPY-Daily-v0', help='Select the environment to run')
args = parser.parse_args()
train = True
if train:
rang = 100
else:
rang = 1
# collect the last 10 time frames (10 days for daily env) and use that to make a prediction for current action
time_frame = 10
time_frame_counter = 0
# train on this batch size
batch_size = 32
env = fingym.make(args.env_id)
# removing time element from state_dim since I'm creating a sequence via time_frame
state_size = env.state_dim - 1
print('state_size: ', state_size)
agent = DQNAgent(state_size, time_frame, train = train)
for i in range(rang):
# init our env
state = env.reset()
# remove time element
state = np.delete(state, 2)
done = False
# init our timeframe
s_timeframe, r_timeframe, ns_timeframe, d_timeframe = reset_timeframe(time_frame, state_size)
# alighn every training iterations
align_every_itt = 15
align_counter = 0
while not done:
action = agent.act(state)
next_state, reward, done, info = env.step(action)
print('action: ', action)
print('reward: ', reward)
# remove time element
if len(state) > state_size:
state = np.delete(state, 2)
next_state = np.delete(next_state, 2)
if time_frame_counter >= time_frame:
agent.store(s_timeframe, action, r_timeframe, ns_timeframe, d_timeframe)
s_timeframe[:-1] = s_timeframe[1:]
r_timeframe[:-1] = r_timeframe[1:]
ns_timeframe[:-1] = ns_timeframe[1:]
d_timeframe[:-1] = d_timeframe[1:]
time_frame_counter-=1
s_timeframe[time_frame_counter] = state
r_timeframe[time_frame_counter] = reward
ns_timeframe[time_frame_counter] = next_state
d_timeframe[time_frame_counter] = done
time_frame_counter+=1
if len(agent.experience_replay) > batch_size:
print('retrain')
agent.retrain(batch_size)
if align_counter >= align_every_itt:
print('align target model')
agent.align_target_model()
align_counter = 0
print(info)
state = next_state
align_counter+=1
Results
Unfortunately this agent has difficulty finding a good policy and ultimately gets stuck taking a single action every time.
Some thoughts on how to improve this agent is to give it more context via feature extraction. For example, giving it more input data such as current events sentiment, highest and lowest values in some time period, etc. But feature extraction takes effort, so we move away from this agent to try other strategies.
Deep neuroevolution
This code creates a SPY-Daily-v0 environment and hundreds of deep neural network agents with weights randomly generated via uniform distributions. Agents are compared to one another to find the fittest (obtained highest rewards). All but the top N agents are discarted. The top N agents are used to repopulate our population much like asexual reproduction. Children contain mutations so that they aren’t identical to their parents. The process is repeated across many generations until the fittest agents are obtained. Based on the following paper.
This agent requires tensorflow, as of Feb. 12 2020, we recommend the nightly build due to a memory leak issue.
There are two techniques created: asexual and sexual reproduction. The only difference being that sexual reproduction uses crossover (genes from both parents)
Run examples/agents/evolutionary_agent.py
Run examples/agents/evolutionary_agent_w_crossover.py
The training loop creates 400 agents and runs them through the environment multiple times and takes the average score. The top 20 agents are selected to repopulate the environment. Some mutation and crossover is applied for diversity. This is done through normal distribution random generated values. As a note, the top 20 agents are kept in the new generation to ensure that mutation doesn’t make worse agents.
The main loop looks like this:
if __name__ == '__main__':
parser = argparse.ArgumentParser(description=None)
parser.add_argument('env_id', nargs='?', default='SPY-Daily-v0', help='Select the environment to run')
args = parser.parse_args()
env = fingym.make(args.env_id)
# removing time element from state_dim
state_size = env.state_dim - 1
print('state_size: ', state_size)
time_frame = 30
num_agents = 400
agents = create_random_agents(num_agents, state_size, time_frame)
# first agent gets saved weights
dirname = os.path.dirname(__file__)
os.path.join(dirname,'evo_weights.h5')
weights_file=os.path.join(dirname,'evo_weights.h5')
if os.path.exists(weights_file):
print('loading existing weights')
agents[0].model.load_weights(weights_file)
# how many top agents to consider as parents
top_limit = 20
# run evolution until x generations
generations = 1000
elite_index = None
for generation in range(generations):
rewards = run_agents_n_times(env,agents,3) # average of x times
# sort by rewards
sorted_parent_indexes = np.argsort(rewards)[::-1][:top_limit]
top_rewards = []
for best_parent in sorted_parent_indexes:
top_rewards.append(rewards[best_parent])
print("Generation ", generation, " | Mean rewards: ", np.mean(rewards), " | Mean of top 5: ",np.mean(top_rewards[:5]))
print("Top ",top_limit," scores", sorted_parent_indexes)
print("Rewards for top: ",top_rewards)
children_agents, elite_index = return_children(env, agents, sorted_parent_indexes, elite_index)
agents = children_agents
Results
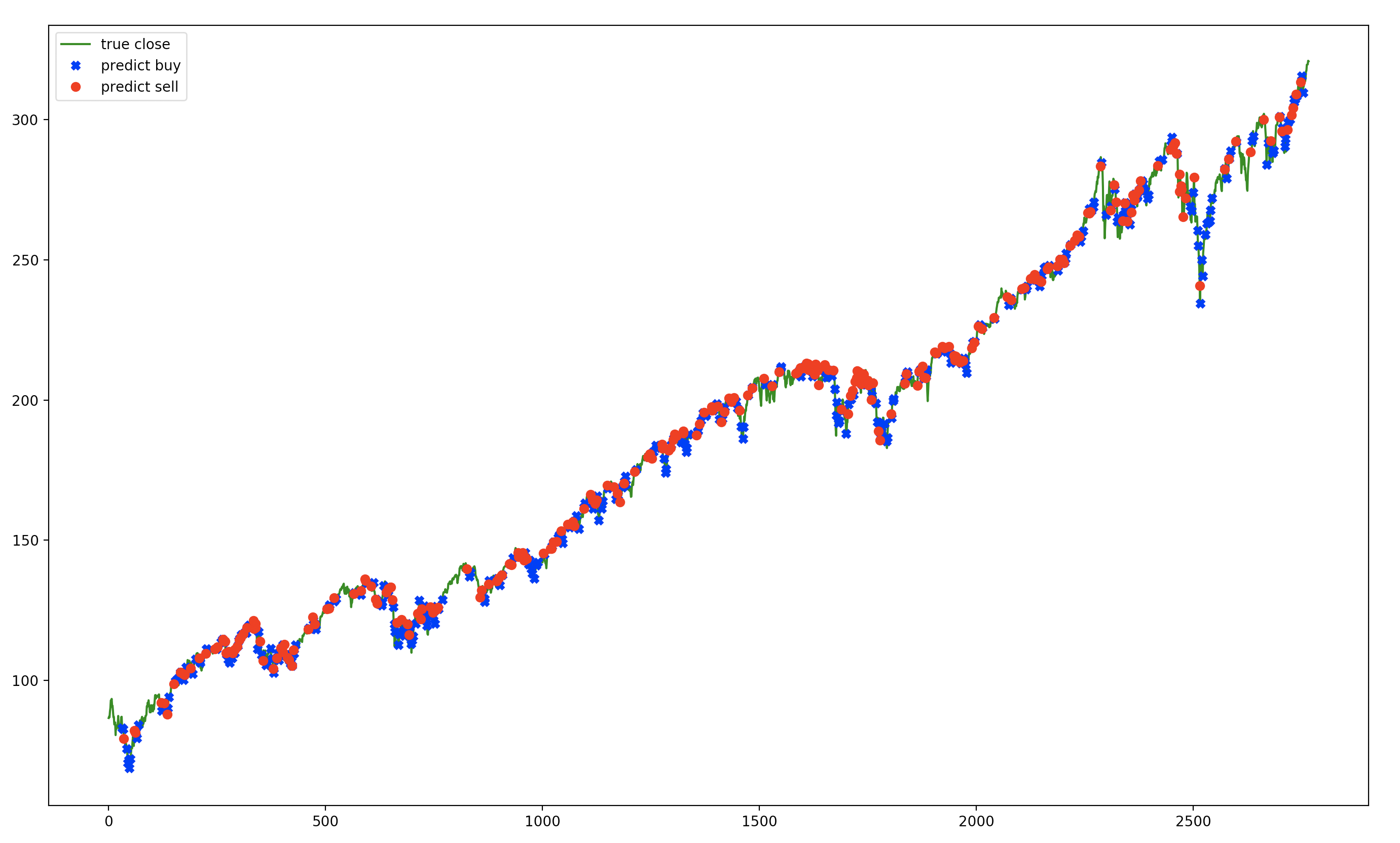
Turns out this agent beats the buy and hold strategy. Remember buy and hold gave us a reward of 92848 after 10 years.
Evolutionary agents beats it right from the start and improves it over generations:
Generation 0 | Mean rewards: 57359.43331030005 | Mean of top 5: 99890.59519999995
Generation 1 | Mean rewards: 82531.03777689998 | Mean of top 5: 105624.93686000006
Generation 2 | Mean rewards: 86718.46527845002 | Mean of top 5: 107301.62140000006
Generation 3 | Mean rewards: 90612.0291022 | Mean of top 5: 108621.7784000001
Generation 4 | Mean rewards: 90634.85884410002 | Mean of top 5: 109371.26040000007
The best agents:
Elite selected with index 276 and score 105707.33
Elite selected with index 330 and score 106712.48000000003
Elite selected with index 180 and score 107936.29000000007
Elite selected with index 27 and score 110383.51000000029
Elite selected with index 399 and score 110383.51000000029
Upon closer inspection, this agent learns to buy early on and hold, so is not much different from the buy and hold strategy.
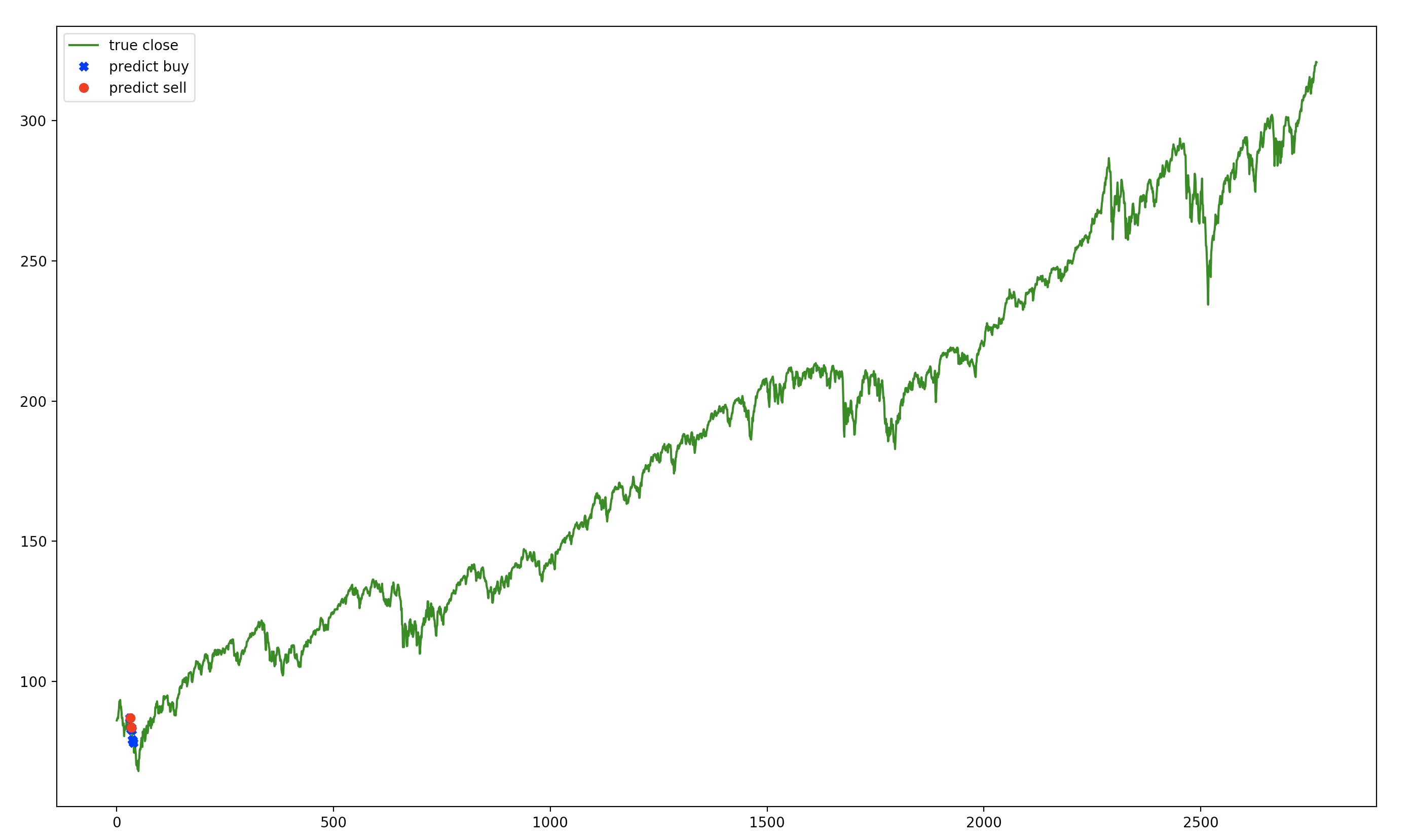
It seems it overfits the data and chooses the best point to buy and hold.
Deep evolution
https://openai.com/blog/evolution-strategies/
This code creates a SPY-Daily-v0 environment and one agent with randomly initialized weights. The optimization of the agent is a guess and check process. The agent weights are updated via finite differencing and no back propagation is needed. This approach is easy to parallelize and has less computational needs.
Run examples/agents/deep_evolution.py
This agent requires ray to run multiple agents in parallel and train faster.
The model is just an array of randomly initialized parameters and a function for forward propagation:
class Model:
def __init__(self, input_size, layer_size, output_size):
self.weights = [
np.random.randn(input_size, layer_size),
np.random.randn(layer_size, output_size),
np.random.randn(layer_size, 1),
np.random.randn(1, layer_size)
]
def predict(self, inputs):
feed = np.dot(inputs, self.weights[0]) + self.weights[-1]
decision = np.dot(feed, self.weights[1])
buy = np.dot(feed, self.weights[2])
return decision, buy
def get_weights(self):
return self.weights
def set_weights(self, weights):
self.weights = weights
The agent contains a model and the strategy:
class Agent:
def __init__(self, model, state_size, time_frame):
self.model = model
self.time_frame = time_frame
self.state_size = state_size
self.state_fifo = deque(maxlen=self.time_frame)
self.max_shares_to_trade_at_once = CONFIG['max_shares_to_trade_at_once']
self.des = Deep_Evolution_Strategy(self.model.get_weights())
def act(self,state):
self.state_fifo.append(state)
# do nothing for the first time frames until we can start the prediction
if len(self.state_fifo) < self.time_frame:
return np.zeros(2)
state = np.array(list(self.state_fifo))
state = np.reshape(state,(self.state_size*self.time_frame,1))
#print(state)
decision, buy = self.model.predict(state.T)
# print('decision: ', decision)
# print('buy: ', buy)
return [np.argmax(decision[0]), min(self.max_shares_to_trade_at_once,max(int(buy[0]),0))]
def fit(self, iterations, checkpoint):
self.des.train(iterations, print_every = checkpoint)
The strategy’s job is to find the best parameters based on all of the population’s weights.
class Deep_Evolution_Strategy:
def __init__(self, weights):
self.weights = weights
self.population_size = CONFIG['population_size']
self.sigma = CONFIG['sigma']
self.learning_rate = CONFIG['learning_rate']
def _get_weight_from_population(self,weights, population):
weights_population = []
for index, i in enumerate(population):
jittered = self.sigma * i
weights_population.append(weights[index] + jittered)
return weights_population
def get_weights(self):
return self.weights
def train(self,epoch = 500, print_every=1):
for i in range(epoch):
population = []
rewards = np.zeros(self.population_size)
for k in range(self.population_size):
x = []
for w in self.weights:
x.append(np.random.randn(*w.shape))
population.append(x)
futures = [reward_function.remote(self._get_weight_from_population(self.weights,population[k])) for k in range(self.population_size)]
rewards = ray.get(futures)
rewards = (rewards - np.mean(rewards)) / np.std(rewards)
for index, w in enumerate(self.weights):
A = np.array([p[index] for p in population])
self.weights[index] = (
w + self.learning_rate / (self.population_size * self.sigma) * np.dot(A.T, rewards).T
)
if (i + 1) % print_every == 0:
print('iter: {}. standard reward: {}'.format(i+1,ray.get(reward_function.remote((self.weights)))))
This strategy returns exeptional results:
iter: 950. standard reward: 258715.4850000006
iter: 960. standard reward: 259706.73000000074
iter: 970. standard reward: 258416.72000000093
iter: 980. standard reward: 260159.72000000047
iter: 990. standard reward: 258908.7600000004
iter: 1000. standard reward: 259261.71000000075
The agent also learns to buy and sell and doesn’t get stuck doign a single action.